Database Index in-depth — how does index actually work? what makes a slow Index?
This is a series inspired from the essence from the book — SQL Performance Explained by Markus Winand, you can learn more by visiting the links from the authors’ website.
Generally speaking, the index can make a search faster. Without an index, the database will go through the whole table and filter all the possible matches which, you can imagine, is slow. However, do you know sometimes the index makes the search slower instead?
Knowing the index makes the search fast is not enough. In order to optimize more complex SQL, it’s important to know how the index actually works.
Database Index
An index is a special structure in the database that is build using CREATE INDEX statements. It creates a new data structure that refers to a certain table.
CREATE INDEX index_users_on_age ON users (age);It’s important to know that the index requires its own disk space and holds a copy of the indexed table data. That means the index is pure redundancy.
Why does an index make searching fast?
Searching in the database is like searching in a dictionary. The key concept of searching in a database index is that all entries are arranged in a well-defined order. Therefore, finding data in an ordered data set is fast.
Challenge
The challenging part for the database index is it must process insert ,delete and update statements fast, keeping the index order without moving large amounts of data.
As we know, inserting data in an array is SLOW because it’s not possible to store the data sequentially without moving the following elements to make room for the new one. And moving a large number of elements is very time-consuming.

How does the database overcome?
The database combines two data structures to meet the challenge — a doubly linked list and a search tree.
Why is a tree a good data structure for a database?
- Searching for a particular value is fast (logarithmic time)
- Inserting/deleting a value you’ve already found is fast (constant time to rebalance)
- Traversing a range of values is fast
Why linked list?
- enables the database to read the index back and forwards
- make INSERT super fast — only need to change some pointers

Combining these two data structures, the database is able to satisfy the fast search, fast insert, deletion, and update.
Noted that Indexes can be implemented using a variety of data structures. There’s no standard defining how to create an index. — see more in Wikipedia
Index architecture
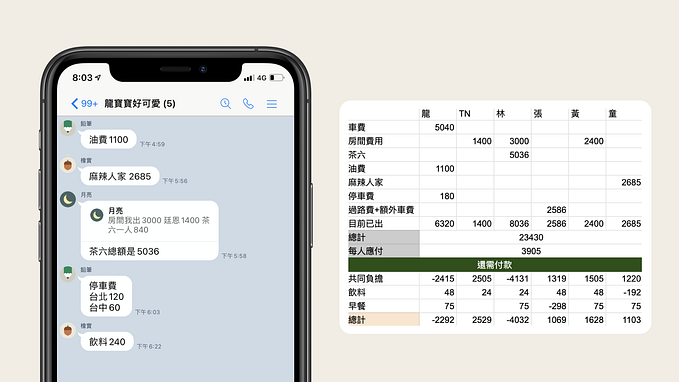
Following is the illustration of indexing age column on users table created by following SQL commands:
CREATE INDEX index_users_on_age ON users (age);Let’s say we want to search all the users whose age is 16:
SELECT * FROM users
WHERE users.age = 16;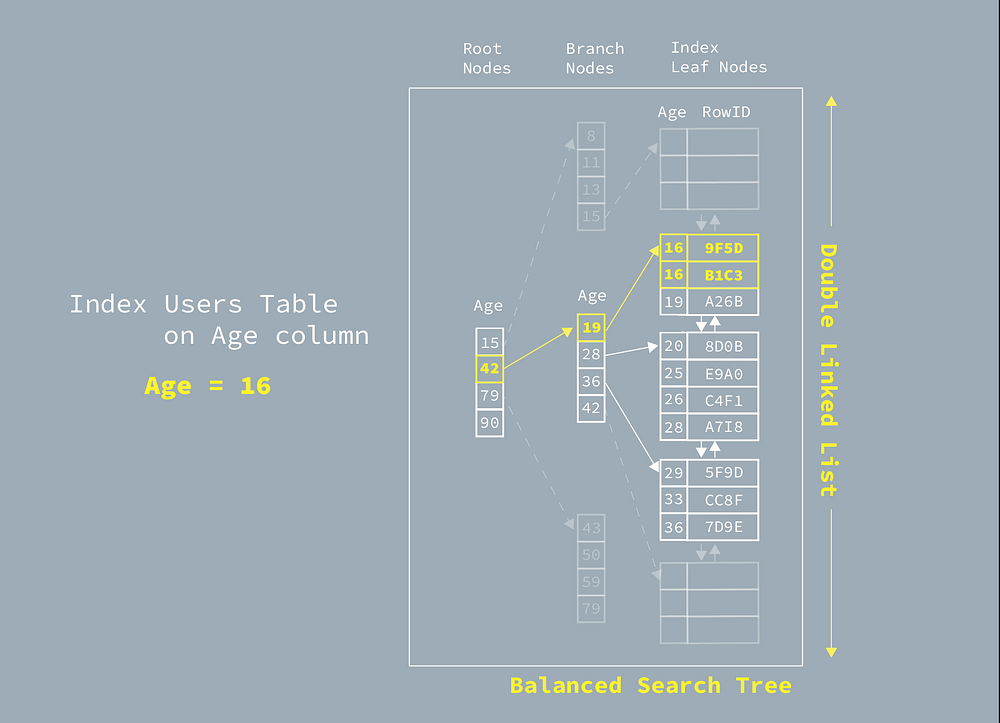
The yellow path highlighted in the illustration is the search path using an index search. We can focus on the key fragments and structures from the graph first:
Balanced Search Tree— is built fromusers.agecolumn in sorted order on each level of nodes, which, as mentioned above, is able to search in logarithmical time.Double Linked List— As we know, it’s possible to have multiple results in theWHERESQL. Apart from searching in the balanced tree in different levels, the database will also need to travel in, so-called,Index Leaf Nodesto find every match value. It is built as aDouble Linked Listwhich make it very easy to travel back and forward.

RowID— After searching within the index, the database still needs to access the actual table to fetch the row values listed in theSELECTquery. The database makes it works by saving theRowIDorRIDin the index, which refers to the actual table entry position.
Lookup Process
Inference from the index structure above, there are three main steps in how the database executes a simple index search. Hence, the search speed depends on the time spent on each step:
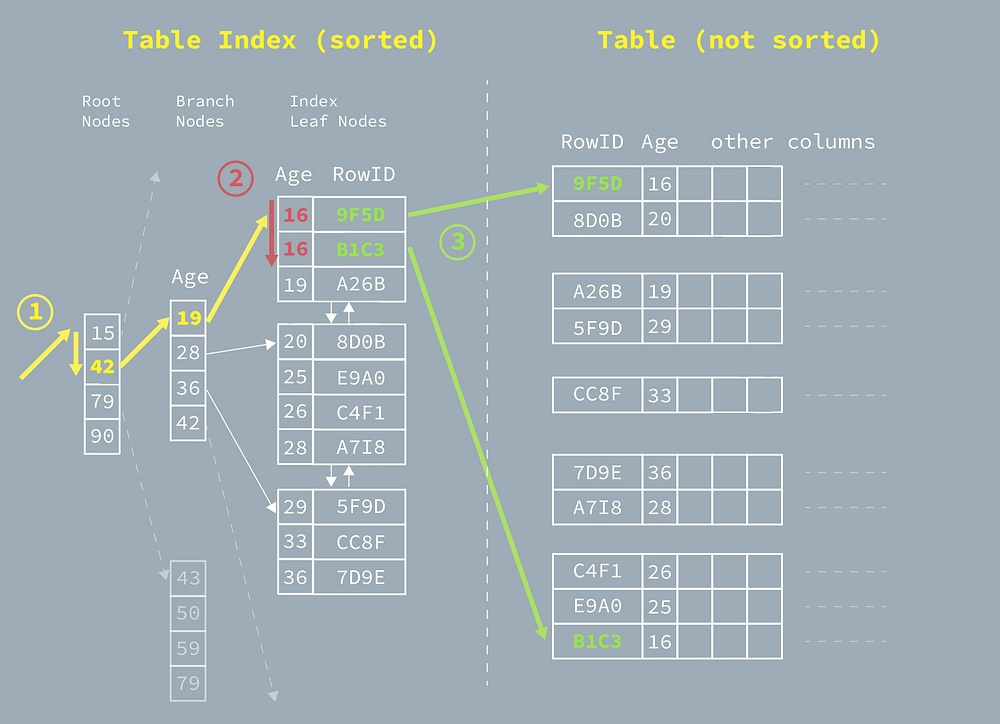
- ① Search in the index tree — B-tree Traversal
Follow the yellow path from the figure, the steps to traverse the tree is in this index is 3, which is related to the depth of the B-tree. This tree contains 4 entries per node which means it can contain up to 64 (4³) entries.
In real-world, databases are able to maximize the entries per node, often hundreds. Usually, the index has a tree depth of 4 or 5, rarely 6. That means you can store 100⁵=10000000000 of entries and search only in 5 steps. Isn’t it crazy?
Tree Traversal is so efficient and works almost instantly even on a huge table as mentioned.
- ② Search in the linked list — following in leaf nodes chain
Consider we are searching users whose age is 16, it’s obvious there are two matching entries in the index. Hence, the database needs to go through all the leaf nodes until it reaches another entry which is not 16, in this case, 19. This process to read through the leaf nodes consumes time.
Although tree traversal is super fast, it’s possible that you have thousands of entries that need to be walk through and slow down the search.
This is one of the factors that make the search slow — even when using the index.
- ③ Access (hit) the actual table
After searching in the tree, the database will get a set of RowID which pointed to the row position of the actual table. The database needs to access the actual table to fetch the actual data.
As we know, the actual table is unsorted. Hence, the matched data is very likely scattered across many table blocks. That means there is additional table access for each hit.
If you are querying 98% of data in the user table, it is very likely that a full table scan will be faster than using an index because accessing the table takes a longer time. This is another operation that might slow down the index lookup.
Wrap Up
In real world, there are many different types of indexes. Every database handles indexes in various different ways. However, the concept is all similar — trying to build a creative structure that matches the needs for fast search and read/write.
In fact, we are able to examine how the database uses an index. You can learn more by searching keywords — execution plans for different databases. For example, Postgres uses EXPLAIN statement to get the actual execution plans and estimated costs.
It is generally believed that the search index is just traversing the tree, however, we learned that there are actually more steps other than that. And that’s the key point that potentially causes a slow index.
Reference
All images were created by the author.